diff --git a/LICENSE b/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..c56eac397b010a42c03fad7def81e23c727b7fde
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,197 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (which shall not include communications that are clearly marked or
+ otherwise designated in writing by the copyright owner as "Not a Contribution").
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to use, reproduce, modify, merge, publish,
+ distribute, sublicense, and/or sell copies of the Work, and to
+ permit persons to whom the Work is furnished to do so, subject to
+ the following conditions:
+
+ The above copyright notice and this permission notice shall be
+ included in all copies or substantial portions of the Work.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, trademark, patent, and
+ other attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright notice to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. When redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and to charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same page as the copyright notice for easier identification within
+ third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/MANIFEST.in b/MANIFEST.in
new file mode 100644
index 0000000000000000000000000000000000000000..9e7c24d0c252c3efcbdec7b9645bea505b427e9a
--- /dev/null
+++ b/MANIFEST.in
@@ -0,0 +1,39 @@
+include README.md
+include LICENSE
+include pyproject.toml
+include MANIFEST.in
+
+# Include images directory for README.md
+recursive-include images *
+
+# Include package data
+recursive-include algorithm *.json
+recursive-include algorithm *.yaml
+recursive-include algorithm *.yml
+recursive-include algorithm *.txt
+recursive-include algorithm *.md
+recursive-include cli *.json
+recursive-include cli *.yaml
+recursive-include cli *.yml
+recursive-include cli *.txt
+recursive-include cli *.md
+
+
+# Include templates and configuration files
+recursive-include lf_algorithm/plugins/*/mcp_servers/*/templates.py
+recursive-include lf_algorithm/plugins/*/mcp_servers/*/mcp_params.py
+
+# Exclude development files
+global-exclude *.pyc
+global-exclude *.pyo
+global-exclude __pycache__
+global-exclude .DS_Store
+global-exclude *.log
+global-exclude .pytest_cache
+global-exclude .mypy_cache
+global-exclude .venv
+global-exclude venv
+global-exclude env
+global-exclude .env
+global-exclude .pypirc
+global-exclude .ruff_cache
diff --git a/README.md b/README.md
index ca0a72acf32f8c6cc6e0d67e3236a79c26ba0acc..ee6f562f3f22ac15681e6b0328fc47188e0e2676 100644
--- a/README.md
+++ b/README.md
@@ -1,12 +1,207 @@
---
-title: Lineagentic Flow
-emoji: ⚡
-colorFrom: blue
-colorTo: purple
+title: lineagentic-flow
+app_file: start_demo_server.py
sdk: gradio
-sdk_version: 5.42.0
-app_file: app.py
-pinned: false
+sdk_version: 5.39.0
---
-Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
+
+
+
+
+## Lineagentic-flow
+
+Lineagentic-flow is an agentic ai solution for building end-to-end data lineage across diverse types of data processing scripts across different platforms. It is designed to be modular and customizable, and can be extended to support new data processing script types. In a nutshell this is what it does:
+
+```
+┌─────────────┐ ┌───────────────────────────────┐ ┌────────────---───┐
+│ source-code │───▶│ lineagentic-flow-algorithm │───▶│ lineage output │
+│ │ │ │ │ │
+└─────────────┘ └───────────────────────────────┘ └──────────────---─┘
+```
+### Features
+
+- Plugin based design pattern, simple to extend and customize.
+- Command line interface for quick analysis.
+- Support for multiple data processing script types (SQL, Python, Airflow Spark, etc.)
+- Simple demo server to run locally and in huggingface spaces.
+
+## Quick Start
+
+### Installation
+
+Install the package from PyPI:
+
+```bash
+pip install lineagentic-flow
+```
+
+### Basic Usage
+
+```python
+import asyncio
+from lf_algorithm.framework_agent import FrameworkAgent
+import logging
+
+logging.basicConfig(
+ level=logging.INFO,
+ format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
+)
+
+async def main():
+ # Create an agent for SQL lineage extraction
+ agent = FrameworkAgent(
+ agent_name="sql-lineage-agent",
+ model_name="gpt-4o-mini",
+ source_code="SELECT id, name FROM users WHERE active = true"
+ )
+
+ # Run the agent to extract lineage
+ result = await agent.run_agent()
+ print(result)
+
+# Run the example
+asyncio.run(main())
+```
+### Supported Agents
+
+Following table shows the current development agents in Lineagentic-flow algorithm:
+
+
+| **Agent Name** | **Done** | **Under Development** | **In Backlog** | **Comment** |
+|----------------------|:--------:|:----------------------:|:--------------:|--------------------------------------|
+| python-lineage_agent | ✓ | | | |
+| airflow_lineage_agent | ✓ | | | |
+| java_lineage_agent | ✓ | | | |
+| spark_lineage_agent | ✓ | | | |
+| sql_lineage_agent | ✓ | | | |
+| flink_lineage_agent | | | ✓ | |
+| beam_lineage_agent | | | ✓ | |
+| shell_lineage_agent | | | ✓ | |
+| scala_lineage_agent | | | ✓ | |
+| dbt_lineage_agent | | | ✓ | |
+
+
+### Environment Variables
+
+Set your API keys:
+
+```bash
+export OPENAI_API_KEY="your-openai-api-key"
+export HF_TOKEN="your-huggingface-token" # Optional
+```
+
+## What are the components of Lineagentic-flow?
+
+- Algorithm module: This is the brain of the Lineagentic-flow. It contains agents, which are implemented as plugins and acting as chain of thought process to extract lineage from different types of data processing scripts. The module is built using a plugin-based design pattern, allowing you to easily develop and integrate your own custom agents.
+
+- CLI module: is for command line around algorithm API and connect to unified service layer
+
+- Demo module: is for teams who want to demo Lineagentic-flow in fast and simple way deployable into huggingface spaces.
+
+#### Command Line Interface (CLI)
+
+Lineagentic-flow provides a powerful CLI tool for quick analysis:
+
+```bash
+# Basic SQL query analysis
+lineagentic analyze --agent-name sql-lineage-agent --query "SELECT user_id, name FROM users WHERE active = true" --verbose
+
+# Analyze with lineage configuration
+lineagentic analyze --agent-name python-lineage-agent --query-file "my_script.py" --verbose
+
+```
+for more details see [CLI documentation](cli/README.md).
+
+### environment variables
+
+- HF_TOKEN (HUGGINGFACE_TOKEN)
+- OPENAI_API_KEY
+
+### Architecture
+
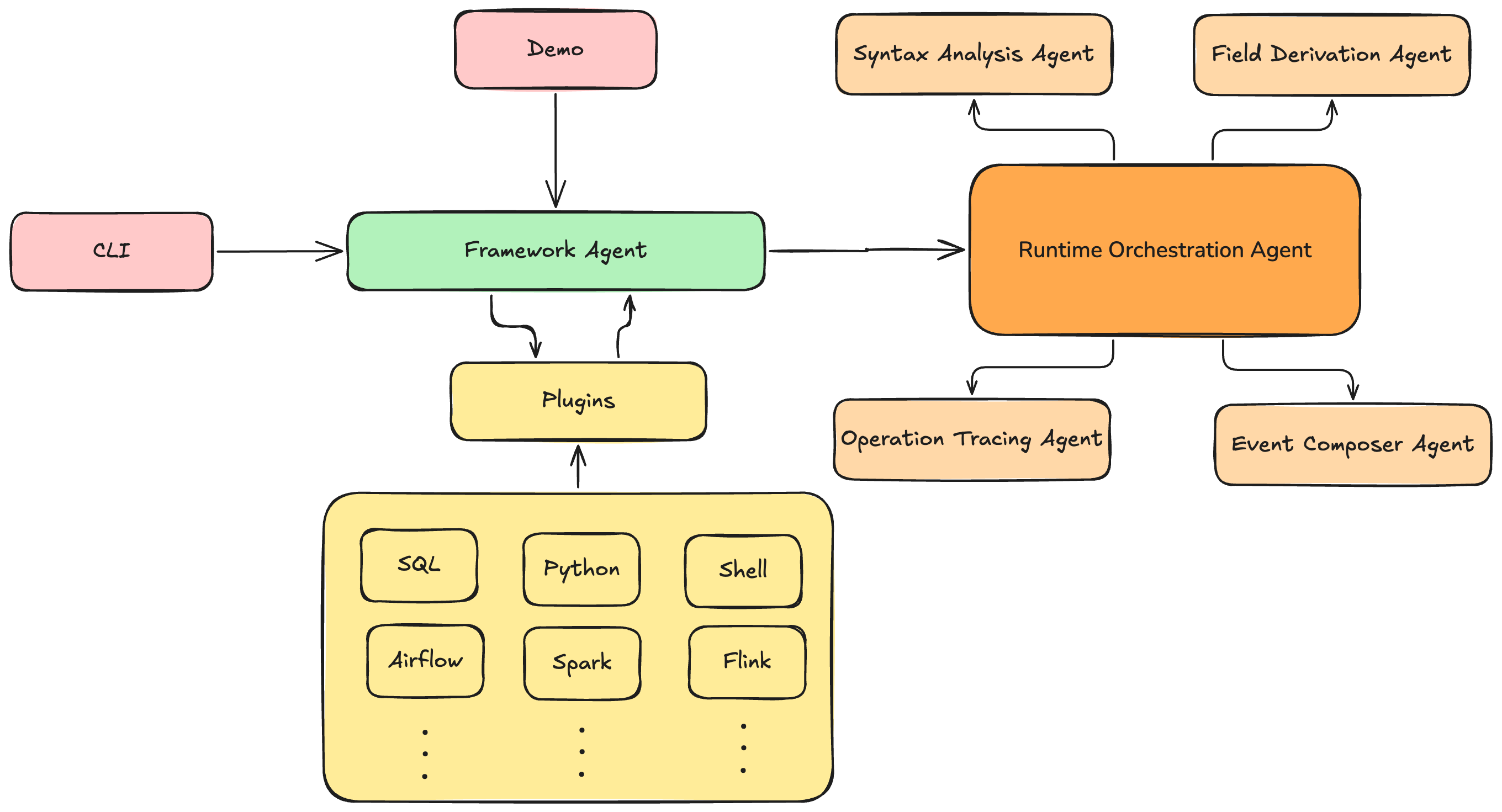
+The following figure illustrates the architecture behind the Lineagentic-flow, which is essentially a multi-layer architecture of backend and agentic AI algorithm that leverages a chain-of-thought process to construct lineage across various script types.
+
+
+
+
+## Mathematic behind algorithm
+
+Following shows mathematic behind each layer of algorithm.
+
+### Agent framework
+The agent framework dose IO operations ,memory management, and prompt engineering according to the script type (T) and its content (C).
+
+$$
+P := f(T, C)
+$$
+
+## Runtime orchestration agent
+
+The runtime orchestration agent orchestrates the execution of the required agents provided by the agent framework (P) by selecting the appropriate agent (A) and its corresponding task (T).
+
+$$
+G=h([\{(A_1, T_1), (A_2, T_2), (A_3, T_3), (A_4, T_4)\}],P)
+$$
+
+## Syntax Analysis Agent
+
+Syntax Analysis agent, analyzes the syntactic structure of the raw script to identify subqueries and nested structures and decompose the script into multiple subscripts.
+
+$$
+\{sa1,⋯,san\}:=h([A_1,T_1],P)
+$$
+
+## Field Derivation Agent
+The Field Derivation agent processes each subscript from syntax analysis agent to derive field-level mapping relationships and processing logic.
+
+$$
+\{fd1,⋯,fdn\}:=h([A_2,T_2],\{sa1,⋯,san\})
+$$
+
+## Operation Tracing Agent
+The Operation Tracing agent analyzes the complex conditions within each subscript identified in syntax analysis agent including filter conditions, join conditions, grouping conditions, and sorting conditions.
+
+$$
+\{ot1,⋯,otn\}:=h([A_3,T_3],\{sa1,⋯,san\})
+$$
+
+## Event Composer Agent
+The Event Composer agent consolidates the results from the syntax analysis agent, the field derivation agent and the operation tracing agent to generate the final lineage result.
+
+$$
+\{A\}:=h([A_4,T_4],\{sa1,⋯,san\},\{fd1,⋯,fdn\},\{ot1,⋯,otn\})
+$$
+
+
+
+## Activation and Deployment
+
+To simplify the usage of Lineagentic-flow, a Makefile has been created to manage various activation and deployment tasks. You can explore the available targets directly within the Makefile. Here you can find different strategies but for more details look into Makefile.
+
+1- to start demo server:
+
+```bash
+make start-demo-server
+```
+2- to do all tests:
+
+```bash
+make test
+```
+3- to build package:
+
+```bash
+make build-package
+```
+4- to clean all stack:
+
+```bash
+make clean-all-stack
+```
+
+5- In order to deploy Lineagentic-flow to Hugging Face Spaces, run the following command ( you need to have huggingface account and put secret keys there if you are going to use paid models):
+
+```bash
+make gradio-deploy
+```
\ No newline at end of file
diff --git a/cli/README.md b/cli/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..c9d8e5061b525e2165da8f1a32dcf73cd0a12017
--- /dev/null
+++ b/cli/README.md
@@ -0,0 +1,167 @@
+# Lineagentic-flow CLI
+
+A command-line interface for the Lineagentic-flow framework that provides agentic data lineage parsing across various data processing script types.
+
+## Installation
+
+The CLI is automatically installed when you install the lineagentic-flow package:
+
+```bash
+pip install -e .
+```
+
+## Usage
+
+The CLI provides two main commands: `analyze` and `field-lineage`.
+
+### Basic Commands
+
+#### Analyze Query/Code for Lineage
+```bash
+lineagentic analyze --agent-name sql-lineage-agent --query "your code here"
+```
+
+
+### Running Analysis
+
+#### Using a Specific Agent
+```bash
+lineagentic analyze --agent-name sql-lineage-agent --query "SELECT a,b FROM table1"
+```
+
+#### Using a File as Input
+```bash
+lineagentic analyze --agent-name python-lineage-agent --query-file path/to/your/script.py
+```
+
+#### Specifying a Different Model
+```bash
+lineagentic analyze --agent-name airflow-lineage-agent --model-name gpt-4o --query "your code here"
+```
+
+#### With Lineage Configuration
+```bash
+lineagentic analyze --agent-name sql-lineage-agent --query "SELECT * FROM users" --job-namespace "my-namespace" --job-name "my-job"
+```
+
+### Output Options
+
+#### Pretty Print Results
+```bash
+lineagentic analyze --agent-name sql --query "your code" --pretty
+```
+
+#### Save Results to File
+```bash
+lineagentic analyze --agent-name sql --query "your code" --output results.json
+```
+
+#### Save Results with Pretty Formatting
+```bash
+lineagentic analyze --agent-name python --query "your code" --output results.json --pretty
+```
+
+#### Enable Verbose Output
+```bash
+lineagentic analyze --agent-name sql --query "your code" --verbose
+```
+
+## Available Agents
+
+- **sql-lineage-agent**: Analyzes SQL queries and scripts (default)
+- **airflow-lineage-agent**: Analyzes Apache Airflow DAGs and workflows
+- **spark-lineage-agent**: Analyzes Apache Spark jobs
+- **python-lineage-agent**: Analyzes Python data processing scripts
+- **java-lineage-agent**: Analyzes Java data processing code
+
+## Commands
+
+### `analyze` Command
+
+Analyzes a query or code for lineage information.
+
+#### Required Arguments
+- Either `--query` or `--query-file` must be specified
+
+### Basic Query Analysis
+```bash
+# Simple SQL query analysis
+lineagentic analyze --agent-name sql-lineage-agent --query "SELECT user_id, name FROM users WHERE active = true"
+
+# Analyze with specific agent
+lineagentic analyze --agent-name sql-lineage-agent --query "SELECT a, b FROM table1 JOIN table2 ON table1.id = table2.id"
+
+# Analyze Python code
+lineagentic analyze --agent-name python-lineage-agent --query "import pandas as pd; df = pd.read_csv('data.csv'); result = df.groupby('category').sum()"
+
+# Analyze Java code
+lineagentic analyze --agent-name java-lineage-agent --query "public class DataProcessor { public void processData() { // processing logic } }"
+
+# Analyze Spark code
+lineagentic analyze --agent-name spark-lineage-agent --query "val df = spark.read.csv('data.csv'); val result = df.groupBy('category').agg(sum('value'))"
+
+# Analyze Airflow DAG
+lineagentic analyze --agent-name airflow-lineage-agent --query "from airflow import DAG; from airflow.operators.python import PythonOperator; dag = DAG('my_dag')"
+```
+
+
+### Reading from File
+```bash
+# Analyze query from file
+lineagentic analyze --agent-name sql-lineage-agent --query-file "queries/user_analysis.sql"
+
+# Analyze Python script from file
+lineagentic analyze --agent-name python-lineage-agent --query-file "scripts/data_processing.py"
+```
+
+### Output Options
+```bash
+# Save results to file
+lineagentic analyze --agent-name sql-lineage-agent --query "SELECT * FROM users" --output "results.json"
+
+# Pretty print results
+lineagentic analyze --agent-name sql-lineage-agent --query "SELECT * FROM users" --pretty
+
+# Verbose output
+lineagentic analyze --agent-name sql-lineage-agent --query "SELECT * FROM users" --verbose
+
+# Don't save to database
+lineagentic analyze --agent-name sql-lineage-agent --query "SELECT * FROM users" --no-save
+
+# Don't save to Neo4j
+lineagentic analyze --agent-name sql-lineage-agent --query "SELECT * FROM users" --no-neo4j
+```
+
+
+
+## Common Output Options
+
+Both commands support these output options:
+
+- `--output`: Output file path for results (JSON format)
+- `--pretty`: Pretty print the output
+- `--verbose`: Enable verbose output
+
+## Error Handling
+
+The CLI provides clear error messages for common issues:
+
+- Missing required arguments
+- File not found errors
+- Agent execution errors
+- Invalid agent names
+
+## Development
+
+To run the CLI in development mode:
+
+```bash
+python -m cli.main --help
+```
+
+To run a specific command:
+
+```bash
+python -m cli.main analyze --agent-name sql --query "SELECT 1" --pretty
+```
+
diff --git a/cli/__init__.py b/cli/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..361b1d180b53f5a548163faa2419bd931cfbabaa
--- /dev/null
+++ b/cli/__init__.py
@@ -0,0 +1,5 @@
+"""
+CLI package for lineagentic framework.
+"""
+
+__version__ = "0.1.0"
\ No newline at end of file
diff --git a/cli/main.py b/cli/main.py
new file mode 100644
index 0000000000000000000000000000000000000000..b56a8602cb1b005e1b0d7ce17f2267a38d538105
--- /dev/null
+++ b/cli/main.py
@@ -0,0 +1,238 @@
+#!/usr/bin/env python3
+"""
+Main CLI entry point for lineagentic framework.
+"""
+
+import asyncio
+import argparse
+import sys
+import os
+import logging
+from pathlib import Path
+
+# Add the project root to the Python path
+project_root = Path(__file__).parent.parent
+sys.path.insert(0, str(project_root))
+
+from lf_algorithm.framework_agent import FrameworkAgent
+
+
+def configure_logging(verbose: bool = False, quiet: bool = False):
+ """Configure logging for the CLI application."""
+ if quiet:
+ # Quiet mode: only show errors
+ logging.basicConfig(
+ level=logging.ERROR,
+ format='%(levelname)s: %(message)s'
+ )
+ elif verbose:
+ # Verbose mode: show all logs with detailed format
+ logging.basicConfig(
+ level=logging.INFO,
+ format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
+ datefmt='%Y-%m-%d %H:%M:%S'
+ )
+ else:
+ # Normal mode: show only important logs with clean format
+ logging.basicConfig(
+ level=logging.WARNING, # Only show warnings and errors by default
+ format='%(levelname)s: %(message)s'
+ )
+
+ # Set specific loggers to INFO level for better user experience
+ logging.getLogger('lf_algorithm').setLevel(logging.INFO)
+ logging.getLogger('lf_algorithm.framework_agent').setLevel(logging.INFO)
+ logging.getLogger('lf_algorithm.agent_manager').setLevel(logging.INFO)
+
+ # Suppress noisy server logs from MCP tools
+ logging.getLogger('mcp').setLevel(logging.WARNING)
+ logging.getLogger('agents.mcp').setLevel(logging.WARNING)
+ logging.getLogger('agents.mcp.server').setLevel(logging.WARNING)
+ logging.getLogger('agents.mcp.server.stdio').setLevel(logging.WARNING)
+ logging.getLogger('agents.mcp.server.stdio.stdio').setLevel(logging.WARNING)
+
+ # Suppress MCP library logs specifically
+ logging.getLogger('mcp.server').setLevel(logging.WARNING)
+ logging.getLogger('mcp.server.fastmcp').setLevel(logging.WARNING)
+ logging.getLogger('mcp.server.stdio').setLevel(logging.WARNING)
+
+ # Suppress any logger that contains 'server' in the name
+ for logger_name in logging.root.manager.loggerDict:
+ if 'server' in logger_name.lower():
+ logging.getLogger(logger_name).setLevel(logging.WARNING)
+
+ # Additional MCP-specific suppressions
+ logging.getLogger('mcp.server.stdio.stdio').setLevel(logging.WARNING)
+ logging.getLogger('mcp.server.stdio.stdio.stdio').setLevel(logging.WARNING)
+
+def create_parser():
+ """Create and configure the argument parser."""
+ parser = argparse.ArgumentParser(
+ description="Lineagentic - Agentic approach for code analysis and lineage extraction",
+ formatter_class=argparse.RawDescriptionHelpFormatter,
+ epilog="""
+Examples:
+
+ lineagentic analyze --agent-name sql-lineage-agent --query "SELECT a,b FROM table1"
+ lineagentic analyze --agent-name python-lineage-agent --query-file "my_script.py"
+ """
+ )
+
+ # Create subparsers for the two main operations
+ subparsers = parser.add_subparsers(dest='command', help='Available commands')
+
+ # Analyze query subparser
+ analyze_parser = subparsers.add_parser('analyze', help='Analyze code or query for lineage information')
+ analyze_parser.add_argument(
+ "--agent-name",
+ type=str,
+ default="sql",
+ help="Name of the agent to use (e.g., sql, airflow, spark, python, java) (default: sql)"
+ )
+ analyze_parser.add_argument(
+ "--model-name",
+ type=str,
+ default="gpt-4o-mini",
+ help="Model to use for the agents (default: gpt-4o-mini)"
+ )
+ analyze_parser.add_argument(
+ "--query",
+ type=str,
+ help="Code or query to analyze"
+ )
+ analyze_parser.add_argument(
+ "--query-file",
+ type=str,
+ help="Path to file containing the query/code to analyze"
+ )
+
+ # Common output options
+ analyze_parser.add_argument(
+ "--output",
+ type=str,
+ help="Output file path for results (JSON format)"
+ )
+ analyze_parser.add_argument(
+ "--pretty",
+ action="store_true",
+ help="Pretty print the output"
+ )
+ analyze_parser.add_argument(
+ "--verbose",
+ action="store_true",
+ help="Enable verbose output with detailed logging"
+ )
+ analyze_parser.add_argument(
+ "--quiet",
+ action="store_true",
+ help="Suppress all output except errors"
+ )
+
+ return parser
+
+
+def read_query_file(file_path: str) -> str:
+ """Read query from a file."""
+ try:
+ with open(file_path, 'r', encoding='utf-8') as f:
+ return f.read()
+ except FileNotFoundError:
+ print(f"Error: File '{file_path}' not found.")
+ sys.exit(1)
+ except Exception as e:
+ print(f"Error reading file '{file_path}': {e}")
+ sys.exit(1)
+
+
+
+
+
+def save_output(result, output_file: str = None, pretty: bool = False):
+ """Save or print the result."""
+ # Convert AgentResult to dict if needed
+ if hasattr(result, 'to_dict'):
+ result_dict = result.to_dict()
+ else:
+ result_dict = result
+
+ if output_file:
+ import json
+ with open(output_file, 'w', encoding='utf-8') as f:
+ json.dump(result_dict, f, indent=2 if pretty else None)
+ print(f"Results saved to '{output_file}'")
+ else:
+ if pretty:
+ import json
+ print("\n" + "="*50)
+ print("ANALYSIS RESULTS")
+ print("="*50)
+ print(json.dumps(result_dict, indent=2))
+ print("="*50)
+ else:
+ print("\nResults:", result_dict)
+
+
+async def run_analyze_query(args):
+ """Run analyze_query operation."""
+ logger = logging.getLogger(__name__)
+
+ # Get the query
+ query = args.query
+ if args.query_file:
+ query = read_query_file(args.query_file)
+
+ if not query:
+ logger.error("Either --query or --query-file must be specified.")
+ sys.exit(1)
+
+ logger.info(f"Running agent '{args.agent_name}' with query...")
+
+ try:
+ # Create FrameworkAgent instance
+ agent = FrameworkAgent(
+ agent_name=args.agent_name,
+ model_name=args.model_name,
+ source_code=query
+ )
+
+ # Run the agent
+ result = await agent.run_agent()
+
+ save_output(result, args.output, args.pretty)
+
+ except Exception as e:
+ logger.error(f"Error running agent '{args.agent_name}': {e}")
+ sys.exit(1)
+
+
+
+
+
+async def main_async():
+ """Main CLI function."""
+ parser = create_parser()
+ args = parser.parse_args()
+
+ # Check if a command was provided
+ if not args.command:
+ parser.print_help()
+ sys.exit(1)
+
+ # Configure logging based on verbosity
+ configure_logging(verbose=args.verbose, quiet=args.quiet)
+
+ # Run the appropriate command
+ if args.command == 'analyze':
+ await run_analyze_query(args)
+ else:
+ print(f"Unknown command: {args.command}")
+ sys.exit(1)
+
+
+def main():
+ """Synchronous wrapper for the async main function."""
+ asyncio.run(main_async())
+
+
+if __name__ == "__main__":
+ main()
\ No newline at end of file
diff --git a/demo_server.py b/demo_server.py
new file mode 100644
index 0000000000000000000000000000000000000000..0512fde975b6b5b575d58fcbbb04c9283c5ac2b9
--- /dev/null
+++ b/demo_server.py
@@ -0,0 +1,321 @@
+import gradio as gr
+import asyncio
+import json
+import threading
+import time
+import sys
+import os
+import logging
+from typing import Optional, Dict, Any
+from datetime import datetime
+
+# Import from the published package
+from lf_algorithm import FrameworkAgent
+from lf_algorithm.utils import write_lineage_log
+
+# Configure logging for the demo server
+logging.basicConfig(
+ level=logging.INFO,
+ format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
+ datefmt='%Y-%m-%d %H:%M:%S'
+)
+
+class SQLLineageFrontend:
+ def __init__(self):
+ self.agent_framework = None
+ self.current_results = None
+ self.current_agent_name = None
+ self.log_thread = None
+ self.should_stop_logging = False
+ self.logger = logging.getLogger(__name__)
+
+ def get_visualize_link(self) -> str:
+ """Generate JSONCrack visualization interface for aggregation data"""
+ if self.current_results is None:
+ return """
+
+
📊 Visualization Ready
+
+ After you run analysis and succeed, you need to got to the following link:
+
+ """
+
+ try:
+ # Get the aggregation data - now it's directly the current_results
+ aggregation_data = self.current_results
+
+ # Handle different result types
+ if isinstance(aggregation_data, str):
+ try:
+ # Try to parse as JSON first
+ parsed_data = json.loads(aggregation_data)
+ data_to_encode = parsed_data
+ except json.JSONDecodeError:
+ # If it's not valid JSON, wrap it in a dict
+ data_to_encode = {"aggregation_output": aggregation_data}
+ elif hasattr(aggregation_data, 'to_dict'):
+ # Handle AgentResult objects
+ data_to_encode = aggregation_data.to_dict()
+ elif isinstance(aggregation_data, dict):
+ data_to_encode = aggregation_data
+ else:
+ # Fallback for other object types
+ data_to_encode = {"aggregation_output": str(aggregation_data)}
+
+ # Format JSON for display
+ formatted_json = json.dumps(data_to_encode, indent=2)
+
+ return f"""
+
+
+ ✅ Analysis Complete! Ready for Visualization
+
+
+ 📋 Steps to visualize your results:
+ 1. Click "Open JSONCrack Editor" below
+ 2. Click "Copy JSON" button or click the JSON data below to select all
+ 3. Paste it into the JSONCrack editor
+
"
+
+ def get_logs_html(self) -> str:
+ """Generate HTML for live logs display"""
+ if self.current_agent_name is None:
+ return "
No agent initialized yet
"
+
+ return f"""
+
+ 📝 Logging Status for Agent: {self.current_agent_name}
+
+
+ ✅ Standard Python Logging Active
+ • All logs are being captured by the application's logging system
+ • Check your console/terminal for real-time log output
+ • Logs include detailed information about agent execution
+ • Structured logging with timestamps and log levels
+
+ 📋 Log Types Available:
+ • INFO - General information and progress
+ • DEBUG - Detailed debugging information
+ • WARNING - Warning messages
+ • ERROR - Error messages
+
+ 🔍 What You'll See:
+ • Agent initialization and configuration
+ • MCP tool interactions and responses
+ • Analysis progress and completion status
+ • Any errors or warnings during execution
+
+
"""
+
+ def test_log_writing(self):
+ """Test function to write a sample log entry"""
+ if self.current_agent_name:
+ try:
+ write_lineage_log(self.current_agent_name, "test", "Test log entry from frontend")
+ self.logger.info(f"Test log written successfully for agent: {self.current_agent_name}")
+ return f"✅ Test log written successfully for agent: {self.current_agent_name}! Check your console output."
+ except Exception as e:
+ self.logger.error(f"Failed to write test log: {e}")
+ return f"❌ Failed to write test log: {e}"
+ else:
+ return "⚠️ Please initialize an agent first by running an analysis"
+
+ def get_results_info(self) -> str:
+ """Get information about the current results"""
+ if self.current_results is None:
+ return "No results available yet"
+
+ if isinstance(self.current_results, dict) and "error" in self.current_results:
+ return f"Error in results: {self.current_results['error']}"
+
+ if hasattr(self.current_results, 'to_dict'):
+ # AgentResult object
+ result_dict = self.current_results.to_dict()
+ inputs_count = len(result_dict.get('inputs', []))
+ outputs_count = len(result_dict.get('outputs', []))
+ return f"✅ Structured results with {inputs_count} input(s) and {outputs_count} output(s)"
+
+ if isinstance(self.current_results, dict):
+ return f"✅ Dictionary results with {len(self.current_results)} keys"
+
+ return f"✅ Results type: {type(self.current_results).__name__}"
+
+ async def run_analysis(self, agent_name: str, model_name: str, query: str):
+ """Run SQL lineage analysis"""
+ try:
+ # Validate input
+ if not query or not query.strip():
+ return "❌ Error: Query cannot be empty. Please provide a valid query for analysis."
+
+ self.logger.info(f"Starting analysis with agent: {agent_name}, model: {model_name}")
+
+ # Initialize the agent framework with simplified constructor
+ self.agent_framework = FrameworkAgent(
+ agent_name=agent_name,
+ model_name=model_name,
+ source_code=query.strip()
+ )
+ self.current_agent_name = agent_name
+
+ self.logger.info(f"Agent framework initialized. Running analysis...")
+
+ # Run the analysis using the structured results method
+ results = await self.agent_framework.run_agent()
+ self.current_results = results
+
+ # Check if we got an error response
+ if isinstance(results, dict) and "error" in results:
+ self.logger.error(f"Analysis failed: {results['error']}")
+ return f"❌ Analysis failed: {results['error']}"
+
+ self.logger.info(f"Analysis completed successfully for agent: {agent_name}")
+
+ return f"""✅ Analysis completed successfully! Results are now available in the visualization section.
+ Click 'Open JSONCrack Editor' to visualize your data lineage.
+
+ If you want to set up your own local development environment or deploy this in production,
+ please refer to the GitHub repository mentioned above."""
+
+ except ValueError as ve:
+ self.logger.error(f"Validation error: {ve}")
+ return f"❌ Validation error: {str(ve)}"
+ except Exception as e:
+ self.logger.error(f"Error running analysis: {e}")
+ return f"❌ Error running analysis: {str(e)}"
+
+ def run_analysis_sync(self, agent_name: str, model_name: str, query: str):
+ """Synchronous wrapper for run_analysis"""
+ return asyncio.run(self.run_analysis(agent_name, model_name, query))
+
+ def create_ui(self):
+ """Create the Gradio interface"""
+ with gr.Blocks(title="SQL Lineage Analysis", fill_width=True) as ui:
+
+ gr.Markdown('